Co se skrývá pod pojmem "umělá inteligence"?
Umělá inteligence (AI - z anglického Artificial Inteligence), velmi zjednodušeně řečeno, je obecně soustava tisíců, miliónu nebo dnes již i miliard mini výpočetních virtuálních jednotek vzájemně propojených v několika či mnoha různých vrstvách. Každá mini-jednotka (někdy označovaná jako neuron) je propojena s různým množstvím podobných stejných mini-jednotek v rámci své vrstvy a i v rámci nejbližší předcházející a následující vrstvy. To jak jsou jednotlivé vrstvy koncipované, včetně jejich základního propojení, závisí na použitém typu systému (někdy se říká neuronové sítě, díky rámcové podobnosti s propojením neuronů v mozcích živočichů).
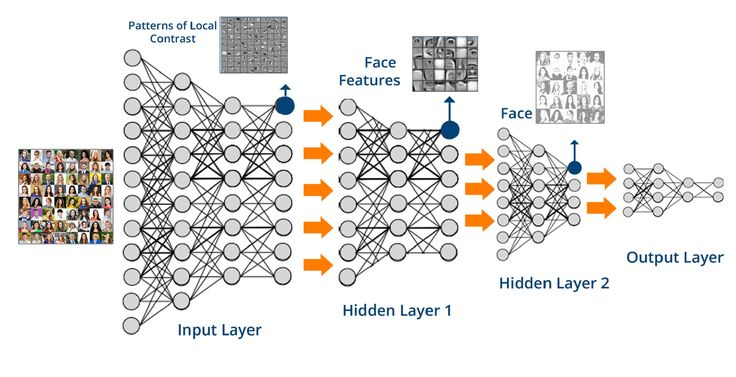
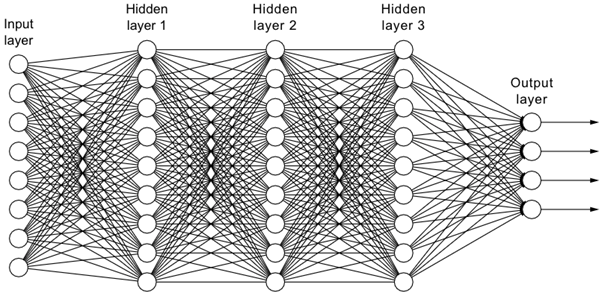
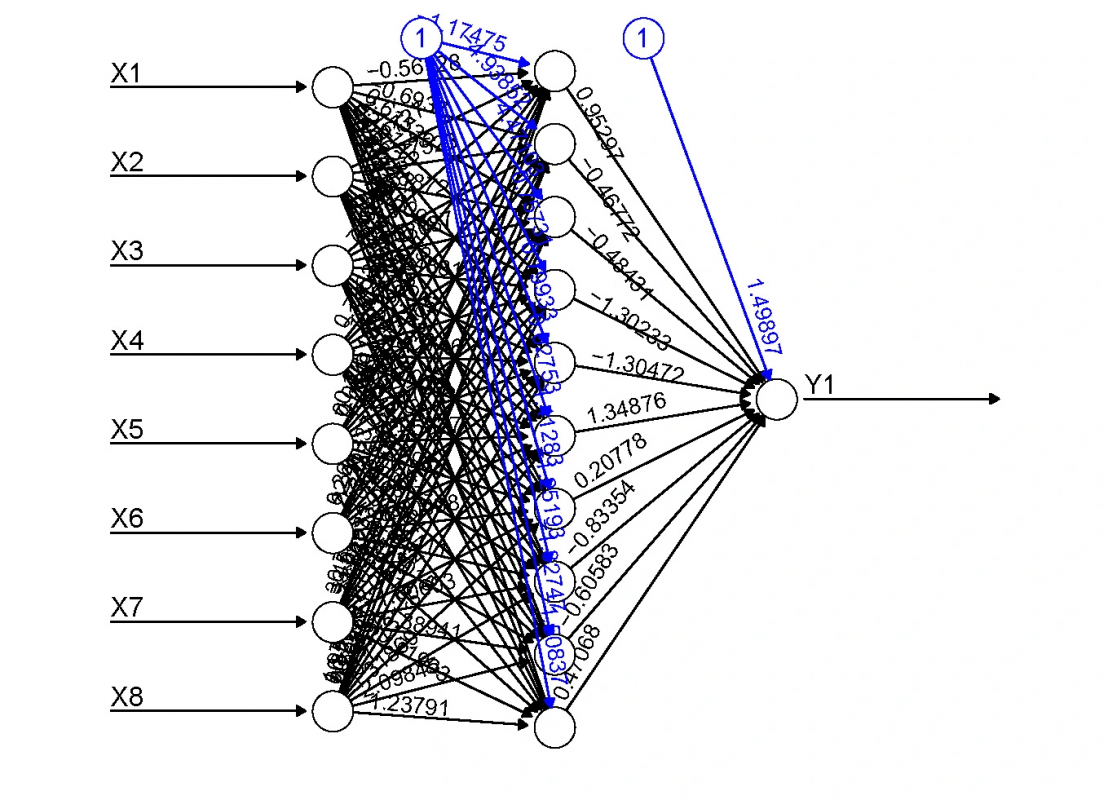
Příklad sítě systému "umělé inteligence" typu DL (DeepLearning) obvykle používané pro vyhodnocování obrazu.
Uvedená propojení si však nesmíte představovat jako nějaké fyzické (mechanické) cestičky, ale spíše jako směrovací tabulky s informacemi v paměti, kam (či jak "intenzivně") se mají data z jakékoliv mini-jednotky dále předávat. Tedy něco vzdáleně podobného jako třeba směrovací tabulka TCP/IP komunikace v síťových (ethernetových) routerech. Jak vypadají, jaká je četnost těchto propojení a co se uchová v každé mini-jednotce za informaci, se definuje v rámci tzv. učení (tréninku) a ověřuje v rámci navazujícího kroku ověřování (validace). Během učení se na vstup základní defaultně nastavené sítě mini-jednotek (neuronové sítě) tvořené vstupní vrstvou, aplikují známá data a následně se výstup sítě porovnává s požadovaným výsledkem. Následně na základě rozdílu od žádoucího výsledku, tedy odchylky o toho žádaného výsledku, se pak zpětným učícím algoritmem posílí ty aktuální cesty mezi jednotkami, které vedou k lepšímu požadovanému výsledku (tedy menší chybě / rozdílu) a naopak oslabí ta propojení, která zhoršovala výsledek (zvětšovala odchylku). Někdy se zde o tom hovoří jako o systému odměny - čím blíže je výsledek cílovému požadavku či referenčnímu výsledku, tím více se systém umělé inteligence odmění. V režimu validace se pak předkládají další data, ale porovnáním se žádoucím výsledkem se počítají přesnosti nebo pravděpodobnosti přesného výsledku bez zpětného režimu učení - jde o takové testování, jak se naučený systém chová. Pokud jsou výsledky během validace v rámci požadované tolerance chyby, tak se systém může uvolnit pro práci. V opačném případě se přistupuje k dalším kolům učení. Nicméně systém se může doučovat i během své již pracovní činnosti, pokud se objeví nové skutečnosti nebo na základě zpětné vazby od operátorů či techniků.
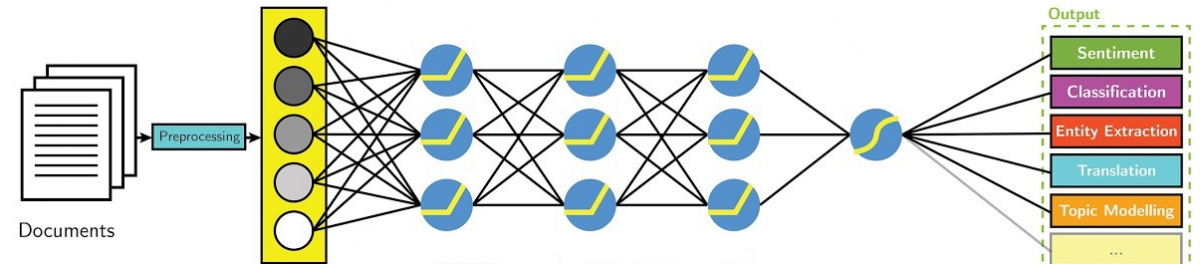
Pod slovem "umělá inteligence" je vhodné si představit různě propojenou rozsáhlou síť matematických operací, která analyzuje či filtruje vstupní data nebo zadané požadavky a za základě shodných nebo podobných prvků s předchozími učícími daty generuje více či méně pravděpodobný výsledek.
 Ve výsledku se tak dá takový naučený systém umělé inteligence představit jako síť různě vzájemně nestejně propojených mini-jednotek, kde každá mini-jednotka v sobě nese nějakou malinkou část celkové informace budoucího výsledku a následné vhodné spojení všech mini-jednotek dá výslednou cílovou sestavu. Tou může být třeba smysluplný text, fungující kód programu, 3D výkres sestavy nějakého stroje, sestava zvuků či not vytvářející vhodnou melodii, výpis částí zákonů či norem týkající se daného konkrétního problému apod. Vhodným definování požadavku na vstupu se "aktivují" potřebné cesty mezi tisíci a milióny mini-jednotek obsahující zlomek k danému tématu a složí se v celý výsledek. Čím univerzálnější tedy má být umělá inteligence, tím více informací z učení musí obsahovat. Systém umělé inteligence specializovaný na jeden konkrétní obor nebo specializaci tedy buď může být menší (mít menší počet mini-jednotek), nebo bude poskytovat přesnější výsledky než systém učený více univerzálně. Platí tedy zde něco podobného jako u lidí (proto se to asi nazývá slovem "inteligence"), tedy že čím větší specializace, tím lepší výsledky v daném oboru specializace, ale na druhou stranu tím horší výsledky z jiné oborové oblasti.
Ve výsledku se tak dá takový naučený systém umělé inteligence představit jako síť různě vzájemně nestejně propojených mini-jednotek, kde každá mini-jednotka v sobě nese nějakou malinkou část celkové informace budoucího výsledku a následné vhodné spojení všech mini-jednotek dá výslednou cílovou sestavu. Tou může být třeba smysluplný text, fungující kód programu, 3D výkres sestavy nějakého stroje, sestava zvuků či not vytvářející vhodnou melodii, výpis částí zákonů či norem týkající se daného konkrétního problému apod. Vhodným definování požadavku na vstupu se "aktivují" potřebné cesty mezi tisíci a milióny mini-jednotek obsahující zlomek k danému tématu a složí se v celý výsledek. Čím univerzálnější tedy má být umělá inteligence, tím více informací z učení musí obsahovat. Systém umělé inteligence specializovaný na jeden konkrétní obor nebo specializaci tedy buď může být menší (mít menší počet mini-jednotek), nebo bude poskytovat přesnější výsledky než systém učený více univerzálně. Platí tedy zde něco podobného jako u lidí (proto se to asi nazývá slovem "inteligence"), tedy že čím větší specializace, tím lepší výsledky v daném oboru specializace, ale na druhou stranu tím horší výsledky z jiné oborové oblasti.
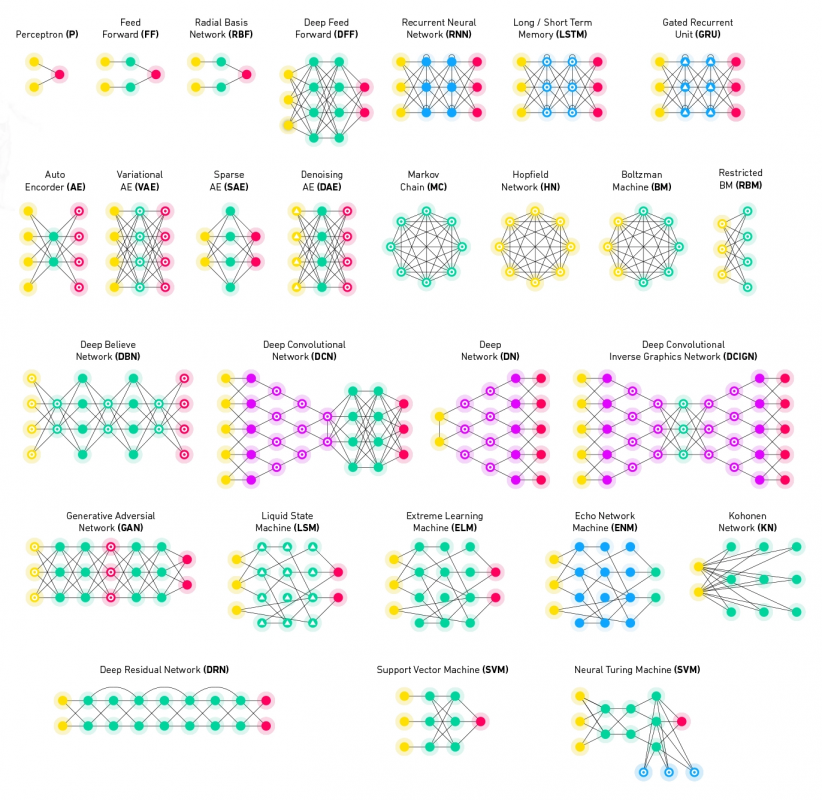
Existuje mnoho různých typů realizace tzv. neuronových sítí, které tvoří základ tzv. umělé inteligence. Každý typ se hodí pro jiné účely.
Filtrovaní a spojování obrovského množství dat
 Pokud to tedy ještě více zjednodušíme, tak systém umělé inteligence nedělá nic jiného, než že analyzuje, filtruje a třídí velké množství dat podle jejich různých specifických parametrů a vytváří si mezi nimi virtuální závislosti a souvislosti. Čím více dat pro danou oblast práce systém umělé inteligence má k dispozici k učení, tedy informací ve formě kombinace "zadaný požadavek-> požadovaný výsledek" (například "Škoda -> osobní auto", "Tatra -> nákladní auto" apod.) nebo případně velkou skupinu podobných informací, které spolu nějak souvisejí (například označenou databázi obrázků obsahující pouze kočky nebo pouze psy), tím přesnější výsledky potom umělá inteligence bude obsahovat. Například auto Škoda Octavia či Škoda Fabia správně použije jako osobní auto a Tatra 815 jako nákladní auto, nebo s přesností na 99% odliší obrázek kočky od obrázku psa. Nicméně nikdy nemůže být žádná umělá inteligence 100% a nemůže správně navrhnout něco, o čem nikdy "neslyšela". S troškou nadsázky řečeno například auto Tatra 603 označí omylem za nákladní auto a bude se třeba pokoušet navrhovat do něj nasypat písek...
Pokud to tedy ještě více zjednodušíme, tak systém umělé inteligence nedělá nic jiného, než že analyzuje, filtruje a třídí velké množství dat podle jejich různých specifických parametrů a vytváří si mezi nimi virtuální závislosti a souvislosti. Čím více dat pro danou oblast práce systém umělé inteligence má k dispozici k učení, tedy informací ve formě kombinace "zadaný požadavek-> požadovaný výsledek" (například "Škoda -> osobní auto", "Tatra -> nákladní auto" apod.) nebo případně velkou skupinu podobných informací, které spolu nějak souvisejí (například označenou databázi obrázků obsahující pouze kočky nebo pouze psy), tím přesnější výsledky potom umělá inteligence bude obsahovat. Například auto Škoda Octavia či Škoda Fabia správně použije jako osobní auto a Tatra 815 jako nákladní auto, nebo s přesností na 99% odliší obrázek kočky od obrázku psa. Nicméně nikdy nemůže být žádná umělá inteligence 100% a nemůže správně navrhnout něco, o čem nikdy "neslyšela". S troškou nadsázky řečeno například auto Tatra 603 označí omylem za nákladní auto a bude se třeba pokoušet navrhovat do něj nasypat písek...
Umělá inteligence tedy může správně vyhodnotit jen informace, data či souvislosti, které obsahují alespoň nějaké vlastnosti, na které byl předtím systém umělé inteligence učen. A tedy co jednou někdo veřejně nebo v rámci neplacené služby dá na síť, může se potenciálně stát zdrojem učení umělé inteligence.
Návrhy za pár sekund, ale který je ten pravý?
 Někdy se říká "co člověk, to názor". To samé by se mohlo říct i o systémech umělé inteligence. I když budou dva stejné systémy naučené na stejných datech, nemusí být (a obvykle ani nejsou) jejich výsledky přesně totožné, tedy nebudou poskytovat zcela stejné výsledky se stejnou pravděpodobností - tedy oba výsledky nemusí být 100% stejné, i když dost často mohou být velmi podobné. Jde totiž o to, že systémy umělé inteligence výsledky sestavují v rámci pravděpodobností, co se nejvíce bude blížit požadovanému výsledku. A tato pravděpodobnost nikdy není 100%, i když se tomu některé výsledky mohou blížit (třeba může být přesnost na 99,99%). Nakonec tak může vzniknout několik různých výsledků, které se budou více či méně blížit splnění požadovaného zadání. To je zásadní rozdíl od klasických logických / sekvenčních programů, kde je z principu funkce přesně jasně dané, kdy jaký výsledek nastane a bude u všech kopií stejného softwaru vždy zcela totožný (nepřesnost výsledku je dána jen limitem bitového rozlišení), tedy systém je zcela předvídatelný.
Někdy se říká "co člověk, to názor". To samé by se mohlo říct i o systémech umělé inteligence. I když budou dva stejné systémy naučené na stejných datech, nemusí být (a obvykle ani nejsou) jejich výsledky přesně totožné, tedy nebudou poskytovat zcela stejné výsledky se stejnou pravděpodobností - tedy oba výsledky nemusí být 100% stejné, i když dost často mohou být velmi podobné. Jde totiž o to, že systémy umělé inteligence výsledky sestavují v rámci pravděpodobností, co se nejvíce bude blížit požadovanému výsledku. A tato pravděpodobnost nikdy není 100%, i když se tomu některé výsledky mohou blížit (třeba může být přesnost na 99,99%). Nakonec tak může vzniknout několik různých výsledků, které se budou více či méně blížit splnění požadovaného zadání. To je zásadní rozdíl od klasických logických / sekvenčních programů, kde je z principu funkce přesně jasně dané, kdy jaký výsledek nastane a bude u všech kopií stejného softwaru vždy zcela totožný (nepřesnost výsledku je dána jen limitem bitového rozlišení), tedy systém je zcela předvídatelný.
V provozní praxi se systémy umělé inteligence tak bude v blízké budoucnosti asi ještě běžnou situací, že si raději necháme vygenerovat i více různých výsledků, například na základě několika malinko odlišných zadávacích specifikací, a pak si vybereme daný konkrétní výsledek, který se bude nejvíce hodit pro daný požadavek - vnější design produktu, jeho funkční vlastnosti, barevnost nebo zaostření obrázku, melodie či zvuk nejvhodnější pro daný okamžik, nejrychlejší, nejjednodušší, nejspolehlivější nebo nejzabezpečenější kód programu nějaké aplikace, prostě dle konkrétního cílového zaměření. A ve výsledku tu tedy musí být někdo (nějaký člověk), který obrazně řečeno "bouchne do stolu" a řekne "ano, toto řešení nejvíce vyhovuje naším potřebám, bezpečnosti, kvalitě, efektivitě" apod. Něco jiného je totiž něco navrhnout a něco jiného následně opravdu fyzicky realizovat, zvláště pokud to má být něco, co má být fyzicky vyráběno, například nějaký hmotný stroj nebo předmět.
AI prompting
 S výše spojeným generování požadovaných výsledků pak těsně souvisí již i zcela nově vznikající pracovní pozice, tzv. AI prompting. Tu patrně bude zastávat nejen v daném oboru školený pracovník, ale v nejlepším případě i člověk s velmi dobrými schopnostmi vyjadřování a formulování požadavků (ať písemného či případně i ústního). Jde totiž o to moderním systémům umělé inteligence co nejpřesněji, ale současně co nejstručněji definovat zadání, co má vlastně vytvořit. Na přesnosti a formě podání požadavku totiž zde nejvíce závisí kvalita výsledku.
S výše spojeným generování požadovaných výsledků pak těsně souvisí již i zcela nově vznikající pracovní pozice, tzv. AI prompting. Tu patrně bude zastávat nejen v daném oboru školený pracovník, ale v nejlepším případě i člověk s velmi dobrými schopnostmi vyjadřování a formulování požadavků (ať písemného či případně i ústního). Jde totiž o to moderním systémům umělé inteligence co nejpřesněji, ale současně co nejstručněji definovat zadání, co má vlastně vytvořit. Na přesnosti a formě podání požadavku totiž zde nejvíce závisí kvalita výsledku.
Závěr - práce na AI, ale odpovědnost na člověku
Jak tedy tzv. umělá inteligence změní budoucnost průmyslu? Z dlouhodobějšího pohledu v rámci desítek let se zdá, že to vlastně aktuálně ani není možné definovat, protože prostě nikdo s určitostí to vlastně neví. A pokud tvrdí, že to ví, tak je to ve skutečnosti jen jeho odhad. Z pohledu vzdálenější budoucnosti totiž pravděpodobně přijdou tak významné změny, že je téměř nemožné teď domyslet jejich vliv.
Z krátkodobějšího výhledu (tak cca do roku 2030) již lze něco předpokládat, byť jen stále s dost velkou nejistotou. Nicméně, pokud do stávajícího vývoje AI nezasáhnou nějak masivně nové celosvětové zákonné regulace, tak pravděpodobně všechnu práci, která nějak zpracovává a požaduje rychlé vyhodnocování dat, prostě budou dělat AI algoritmy. Jejich výsledkem pak bude asi vždy několik vygenerovaných možných scénářů / výstupů (ať již to budou texty, grafiky, videa či programy), které následně bude muset člověk - pracovník osobně vyhodnotit a rozhodnout, které následně z nich použít. Odpovědnost totiž v dohledné době stále zůstane na lidech, protože ty jedině má smysl nějak "perzekuovat" pokud se zmýlí nebo udělají chybu. Jak byste chtěli potrestat umělý systém bez osobních pocitů? Ve výsledku se tak asi práce velkého množství lidí smrskne na tři následující úkoly (nezávisle na tom, v jakém oboru to bude):
krátkodobějšího výhledu (tak cca do roku 2030) již lze něco předpokládat, byť jen stále s dost velkou nejistotou. Nicméně, pokud do stávajícího vývoje AI nezasáhnou nějak masivně nové celosvětové zákonné regulace, tak pravděpodobně všechnu práci, která nějak zpracovává a požaduje rychlé vyhodnocování dat, prostě budou dělat AI algoritmy. Jejich výsledkem pak bude asi vždy několik vygenerovaných možných scénářů / výstupů (ať již to budou texty, grafiky, videa či programy), které následně bude muset člověk - pracovník osobně vyhodnotit a rozhodnout, které následně z nich použít. Odpovědnost totiž v dohledné době stále zůstane na lidech, protože ty jedině má smysl nějak "perzekuovat" pokud se zmýlí nebo udělají chybu. Jak byste chtěli potrestat umělý systém bez osobních pocitů? Ve výsledku se tak asi práce velkého množství lidí smrskne na tři následující úkoly (nezávisle na tom, v jakém oboru to bude):
- 1. Správný AI prompting -> tedy co nejpřesnější vyjádření a zadání požadavku umělé inteligenci v co možná nejstručnějším popisu.
- 2. Kontrola a výběr finálního vhodného řešení -> tedy probrat a otestovat jednotlivé AI vygenerované návrhy a následně jeden vybrat a určit za výsledek práce.
- 3. Obhájit si a případně vyargumentovat, proč byl zvolen zrovna tento daný výsledek AI místo některého z dalších.
Umělá inteligence sice stále bude ještě nějakou dobu určitě fungovat jen jako "neživý", byť sofistikovaný nástroj, ale asi v mnoha lidských povoláních, zaměstnáních a činnostech zmizí ta část práce, kdy bylo nutné se probírat informacemi, analyzovat je, vyhodnocovat jejich smysluplnost a spojovat je do logických a funkčních celků. To AI bude umět lépe a hlavně rychleji, což zatím je stále hlavní požadavek a motor nejen průmyslu.
Odkazy:
- Webové stránky o AI technologiích pro průmysl na webu veletrhu HannoverMesse: https://www.hannovermesse.de/en/news/industry-trends/ai-machine-learning
- Článek "When AI thinks about tomorrow today" na webových stránkách veletrhu HannoverMesse: https://www.hannovermesse.de/en/news/news-articles/when-ai-thinks-about-tomorrow-today
- Webové stránky společnosti aiXbrain : https://www.aixbrain.de/