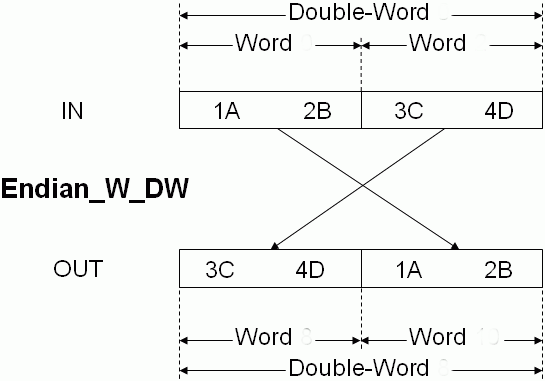
Modbus a 32-bitové hodnoty
 S rostoucí přesností měření mnoha moderní měřících zařízení se dnes stále častěji setkáváme s využitím již 32-bitového formátu naměřených hodnot. S tím pak nutně souvisí i následný požadavek na jejich přenos přes sběrnici do nadřazeného systému (např. PLC, PC nebo HMI). Jedním z velmi rozšířených komunikačních protokolů je Modbus-TCP, zvláště pro svou jednoduchou implementovatelnost díky využívání standardního Ethernetového přenosového / komunikačního systému, poměrně jednoduché struktuře protokolu a celosvětově otevřeném použití bez nutnosti nějakých licencí.
S rostoucí přesností měření mnoha moderní měřících zařízení se dnes stále častěji setkáváme s využitím již 32-bitového formátu naměřených hodnot. S tím pak nutně souvisí i následný požadavek na jejich přenos přes sběrnici do nadřazeného systému (např. PLC, PC nebo HMI). Jedním z velmi rozšířených komunikačních protokolů je Modbus-TCP, zvláště pro svou jednoduchou implementovatelnost díky využívání standardního Ethernetového přenosového / komunikačního systému, poměrně jednoduché struktuře protokolu a celosvětově otevřeném použití bez nutnosti nějakých licencí.
Nicméně v případě jeho použití pro přenos 32-bitových hodnot již můžeme v praxi narazit na problémy určené tím, že díky již poměrně velkému stáří struktury paketu Modbusu, je v něm standardně počítáno s 16-bitovým formátem přenášených hodnot. 32-bitová čísla sice lze také přenášet, nicméně jen jako rozdělené na dvě po sobě jdoucí 16-bitová čísla. To samo osobě je v Modbusu poměrně jednoduché. Prostě se například pro čtení využije funkce "03 Read Holding Register" na adresu registru XY a s tím, že se definuje přenos dvou hodnot (tedy hodnoty v 16-bitovém registru na adrese XY a hned následujícího čísla na adrese XY+1). V mnoha případech je u moderních PLC dokonce přímo připravená funkce Modbus přenosu 32-bitových hodnot, což je však pouze "krabička typu Black box", která však opět uvnitř jen řeší Modbus přenos dvou po sobě jdoucích 16-bitových čísel. Prostě tak je protokol Modbus navržen a s tím je nutné pracovat (v tomto směru je jedno zda Modbus-RTU po staré sériové sběrnici nebo Modbus-TCP využívající Ethernet).

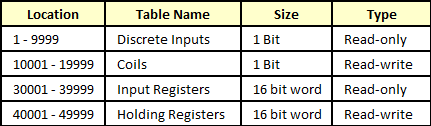
Modbus-RTU nebo Modbus-TCP komunikace sice "jako by" podporuje přenos i 32-bitových hodnot (viz příklad Modbus komunikační tabulky - obr. vlevo), nicméně fyzicky po sběrnici jsou Modbus protokolem vždy přenášeny rozdělené na dvě 16-bitové části (viz tabulka vpravo). V ukázkové komunikační Modbus tabulce (obr. vlevo) je patrné, že hodnoty (položky) s 32bit. čísly zabírají hned dva Modbus registry - např. 40007 a 40008.
"OK, tak ale kde je problém? ", se může někdo zeptat. "Prostě se 32-bitové hodnoty přenesou jako dvě 16-bitové části a po přenosu se zase spojí a je to!". Ano, takto opravdu jednoduše funguje, ale až do té doby, než vzájemně obě komunikují zařízení (např. měřící jednotka / senzor a nějaké PLC) mají odlišnou interpretaci 32-bitových čísel podle toho, jak jsou uložené v jejich paměti. Ano, programátoři jistě vědí, je o větší problém formátů "Big-Endian" a "Little-Endian".
Stručný úvod do problematiky formátů "Big/Little-Endian"
Pod pojmy "Big-Endian" a "Little-Endian" se skrývá historické označení definující způsob ukládání čísel v operační paměti počítače. Přesněji řečeno označuje, v jakém pořadí jsou v paměti uloženy jednotlivé bajty 16- nebo 32-bitového čísla v 8-bitové paměti (tedy kde každé paměťové místo / adresa reprezentuje 8 bitů = 1 bajt). V režimu "Little-Endian" se ukládá nejméně významný bajt (LSB) čísla na první pozici v paměti, zatímco v režimu "Big-Endian" je tomu přesně obráceně, tedy v paměti se na první pozici ukládá nejvyšší bajt čísla (MSB). Metoda "Little-Endian" byla zavedena do praxe z dnešního pohledu v historické době před cca 40 lety u procesorů firmy Intel, zatímco procesory firmy Motorola zavedly režim "Big-Endian".
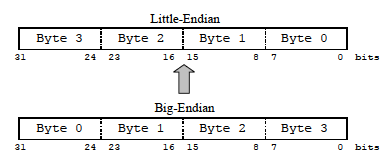
Pořadí uložení bajtů 32-bitového čísla v paměti zařízení se liší podle toho, zda využívá režim "Big-Endian" nebo "Little-Endian".
Například 16-bitové (2-bajtové) číslo reprezentované hexadecimálním zápisem "A41C" bude v případě "Little-Endian" formátu uloženo v paměti v pořadí bajtů "1C A4", zatímco v případě formátu "Big-Endian" v pořadí bajtů "A4 1C". V druhém případě tedy v tomto případě matematický zápis čísla odpovídá i zápisu čísla v paměti.
V případě 32-bitových (4-bajtových) čísel by pak například hodnota "1234A41C" by byla v případě režimu "Little-Endian" v 8-bitové paměti uložena v pořadí bajtů "1C A4 34 12", zatímco v režimu "Big-Endian" v pořadí bajtů "12 34 A4 1C".
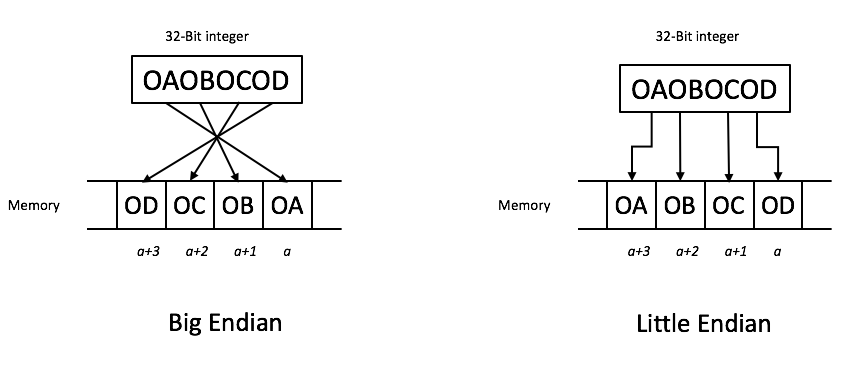
Stejné 32-bitové číslo, které však je v paměti rozdílně zapsané podle použitého formátu ukládání. To může způsobovat problémy při vzájemné komunikaci dvou zařízení, kde každý využívá odlišný formát.
Z pohledu lidského pochopení a přehlednosti zápisu je tedy lepší zápis "Big-Endian". Nicméně z pohledu počítačového hardwaru je výhodnější režim "Little-Endian", protože se v paměti ta samá hodnota může snadno přečíst s různou délku (počtem bitů) bez potřeby změny adresy. Jinak řečeno, se stejnou hodnotou adresy počátku čísla v paměti lze přečíst jak 8-bitovou, tak 16-bitovou, tak 32-bitovou délku čísla. To je výhoda v případě, že se ve stejné paměti současně nacházejí různě promixovány 8-,16- nebo 32-bitové hodnoty. Pak jen stačí vědět kolik je potřeba číst bajtů z dané adresy.
Organizace paměti u PLC a HMI
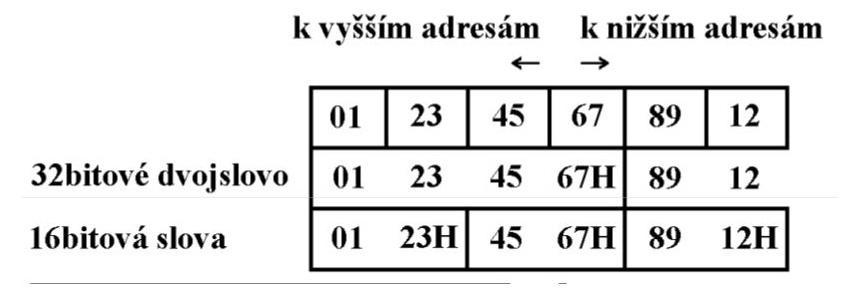 Režim "Little-Endian" se proto stále dost často využívá i v současnosti u moderních PLC či HMI panelů. Ne sice na úrovni jednotlivých bajtů, ale již na vyšší úrovni slov (WORDs), tedy 16-bitových čísel. Paměť zde již není rozdělená po blocích tvořenými jednotlivými bajty (8 bity), ale již po blocích o velikosti 16 bitů, tedy WORD (slovo).
Režim "Little-Endian" se proto stále dost často využívá i v současnosti u moderních PLC či HMI panelů. Ne sice na úrovni jednotlivých bajtů, ale již na vyšší úrovni slov (WORDs), tedy 16-bitových čísel. Paměť zde již není rozdělená po blocích tvořenými jednotlivými bajty (8 bity), ale již po blocích o velikosti 16 bitů, tedy WORD (slovo).
Problematika "Little-Endian", resp. "Big-Endian" je zde tak nutné v praxi řešit pouze v režimu 32-bitových čísel, tedy tzv. DWORD (dvojslovo). Tedy konkrétně 32-bitová hodnota "1234A41C" bude v případě 16-bitové varianty "Little-Endian" uložená v paměti PLC či HMI jako dvě slova v pořadí "A41C" a "1234", zatímco v režimu "Big-Endian" budou obě slova uložena v pořadí "1234" a "A41C".
A to je celý problém, který může v případě Modbus komunikace nejednomu programátoru zamotat hlavu.
Problém prohozených slov
Teď se opět vraťme k našemu 32-/16-bitovému přenosu po Modbusu. Jak je z výše uvedeného patrné, problém s přenosem 32-bitových čísel přes Modbus nastává v situaci, kde jedno zařízení, například senzor používá jiný formát uložení 32-bitového čísla v paměti než druhé zařízení, například řídící PLC či zobrazující HMI.
V praxi například senzor poskytuje horních 16 bitů své naměřené 32-bitové hodnoty ke čtení v Modbus registru s adresou XY a spodních 16 bitů v registru XY+1. Na proti tomu PLC či HMI může ze své pozice očekávat přesný opak, tedy spodních 16 bitů čísla (Lower WORD) v Modbus Registru XY a horních 16 bitů (Higher WORD) v registru XY+1. Tedy například vážící jednotky Laumas nabízí u hodnoty hmotnosti horních 16 bitů = horní slovo (Higher WORD) v registru 40008 a spodních 16 bitů = spodní slovo (Lower WORD) v registru 40009.
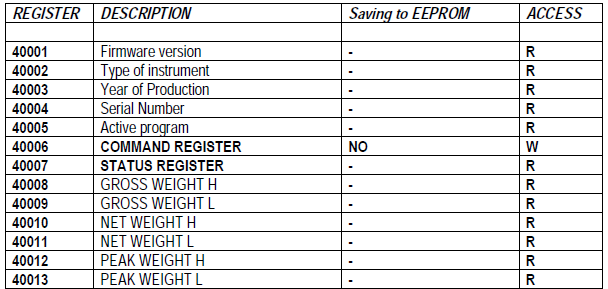

Příklad Modbus registrů vážící jednotky Laumas a její připojení na HMI panel Crouzet / Weintek.
Pokud si tedy za této situace například v HMI panelu (např. Weintek či Crouzet) zvolíte přímo příkaz "přečti 32-bitovou hodnotu ze senzoru z Modbus registru 40008 a tu zobraz na displeji", tak následně k velkému překvapení dostanete na displeji zcela neočekávané číslo. A teď začne bádání, proč hodnota změřená senzorem (měřícím zařízením) neodpovídá hodnotě na displeji HMI?
Na první pohled totiž nemusí být zjevné, že si HMI (či PLC) prostě přeneslo 16-bitů z Modbus registru 40008, které v senzoru reprezentuje horní slovo hodnoty a uloží si je do své paměti do svého 16-bitového registru AB (například 10), které ale u něj reprezentuje spodní slovo. Pak přeneslo 16-bitů z registru 40009, které reprezentuje u senzoru spodní slovo hodnoty a uloží si ho do své paměti hned do následujícího registru AB+1 (tedy 11), který ale u něj reprezentuje horní slovo. Následně HMI pro zobrazení celé 32-bitové hodnoty vezme oba svoje 16-bit. registry (tedy 10 a 11) a složí z nich opět celé 32-bitové číslo.
Tím však HMI nevědomě prohodilo spodních a horních 16 bitů hodnoty senzoru a tedy vlastně vygeneroval zcela jiní číslo - novou hodnotu! A to je celý problém. Senzor/měřící jednotka i HMI panel i Modbus komunikace pracují zcela správně, ale prostě "každý mluví jinou řečí". Řešením v této situaci je tedy nutnost vytvořené jednoduchého "prohazovače".
Jak řešit problém 32-bitového přenosu přes Modbus v praxi?
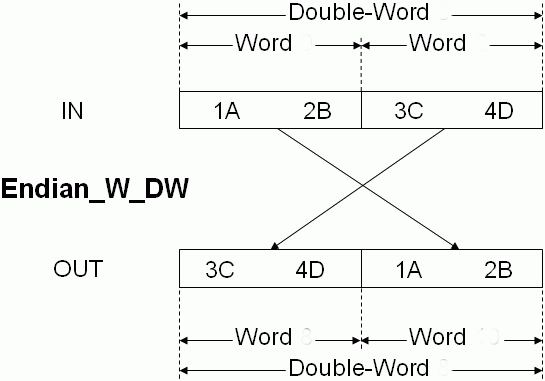 Obvykle na straně Modbus Slave zařízení typu senzor či měřící jednotka s hodnotami nic neuděláte. Prostě tak je to navrženo od výrobce a je to obvykle pevně dané. Řešení tedy musíme podniknout na straně HMI či PLC, tedy nadřazenému zařízení, které hodnoty čte či případně také zapisuje.
Obvykle na straně Modbus Slave zařízení typu senzor či měřící jednotka s hodnotami nic neuděláte. Prostě tak je to navrženo od výrobce a je to obvykle pevně dané. Řešení tedy musíme podniknout na straně HMI či PLC, tedy nadřazenému zařízení, které hodnoty čte či případně také zapisuje.
V tomto směru je v prvé řadě nutné si před programováním / nastavováním komunikace nastudovat, jakou variantu ukládání 32-bitových čísel používané PLC či HMI ve svých registrech (paměti) využívá. Pokud PLC/HMI předpokládá v registru AB očekává nižší slovo (Lower WORD) a v registru AB+1 vyšší slovo (Higher WORD) a naopak senzor v Modbus Registru XY nabízí vyšší slovo (Higher WORD) a v registru XY+1 nižší slovo (Lower WORD), je zde nekompatibilita, kterou je nutné řešit a na straně PLC či HMI udělat vhodnou softwarovou úpravu na prohození horního a spodního slova.
Obecně bývají k dispozici jedna z následujících možnosti:
-
1) Komunikující PLC či HMI podporuje ve svém nastavení volbu pořadí uložení horního a spodního slova 32-bitového čísla. Například PLC IDEC umožňují si zvolit, zda na prvním místě v paměti má být horní nebo spodní slovo 32-bitového čísla.
-
2) Číst přes Modbus celé 32-bitové číslo v pořadí tak, jak je reprezentováno ve senzoru, a následně použít v PLC či HMI nějakou softwarovou funkci, která obě slova (horní a spodní) v paměti prohodí. K tomu buď existují v PLC funkce typu "16-bitový SWAP" nebo to případně lze udělat "ručně" nějakou funkcí typu "MOVE" pro přesun hodnot mezi registry PLC či HMI.
-
3) Číst přes Modbus 32-bitové číslo ze senzoru jako dvě 16-bitová nezávislá čísla a každé samostatně uložit v registrech PLC či HMI již rovnou ve správném pořadí. Tedy nejdříve přes Modbus přečte (přenese) 16-bitové číslo z registru senzoru XY a ta se uloží v PLC/HMI do registru AB+1 a následně přečte 16-bitové číslo z registru senzoru XY+1 a to se uloží v PLC/HMI v registru AB.
Zda zvolit provedení 1), 2) nebo 3) dost záleží na softwarových možnostech (prostředcích) používaného PLC či HMI.
Pro správný zápis 32-bitové hodnoty do senzoru/měřící jednotky z PLC/HMI je pak samozřejmě nutný opačný postup. Tedy buď prohodit obě slova ještě před Modbus zápisem celého 32-bitového čísla nebo provést oddělený prohozený zápis (přenos) dvou 16-bitových čísel do registrů senzoru, který následně s nimi již bude pracovat jako s jedním 32-bitovým číslem.
Závěr
Celá výše uvedená problematika záměny horního a spodního bajtu 32-bitového čísla není složitá na pochopení. Je ale důležité si ji při realizaci Modbus přenosu uvědomovat, nebo si alespoň na ni vzpomenout při práci s 32-bitovými hodnotami. Může to pak někdy ušetřit hodně času strávené hledáním chyby v programu, která se však přímo v programu nenachází, ale je jen "nedorozuměním" v komunikaci. O to hůře se takový problém hledá.
Odkazy:
- Tenzometrické vážní jednotky Laumas: http://www.laumas.it
- Programovatelné automaty IDEC: http://us.idec.com/Catalog/ProductFamily.aspx?FamilyName=Programmable_Controllers_PLCs
- HMI panely Weintek: http://www.weintek.com




Komentáře
Synchronizace
Přijde mi, že článek jen několikrát dokola opakuje triviální fakt, že různá MODBUSová zařízení se neshodnou na tom, v jakém pořadí se přenáší půlky 32-bitového čísla, takže je potřeba dát si na to pozor. To je jistě pravda, ale prození polovin je obvykle naprosto zřejmé. Článek ovšem zcela pomíjí jiný problém, který je mnohem zákeřnější, neboť se neprojevuje při každém čtení: Neumí-li zařízení čtení polovin nějak synchronizovat, je snadné přečíst úplně nesmyslnou hodnotu: například pokud senzor zrovna přechází z 0x0001ffff na 0x00020000, můžete z něj snadno přečíst mezistav 0x0002ffff.