
Běžný reálný problém v učení systémů
 Mnoho výrobců strojů, uživatelů nebo zákazníků dnes stále nechce sdílet data s výrobci / vývojáři zařízení, ale přitom požaduje optimalizace svých závodů i za pomoci strojového učení či umělé inteligence. To ale není možné bez dostatečných dat a kvalitního učení modelů strojového učení. Odborníci tak často hovoří o dilematu distribuovaných dat – uživatel má data, ale nechce nebo nemůže je sdílet a sám je neumí využít, zatímco výrobce / vývojář umí data využít pro vylepšení technologií a systémů, ale nemá k datům přístup.
Mnoho výrobců strojů, uživatelů nebo zákazníků dnes stále nechce sdílet data s výrobci / vývojáři zařízení, ale přitom požaduje optimalizace svých závodů i za pomoci strojového učení či umělé inteligence. To ale není možné bez dostatečných dat a kvalitního učení modelů strojového učení. Odborníci tak často hovoří o dilematu distribuovaných dat – uživatel má data, ale nechce nebo nemůže je sdílet a sám je neumí využít, zatímco výrobce / vývojář umí data využít pro vylepšení technologií a systémů, ale nemá k datům přístup.
Možné řešení - federované učení
Technologické společnosti vědí o tomto problému ve vývoji nových "chytrých" systémů nejen ve spotřební elektronice a IT technice, ale i strojírenství a průmyslu již dlouhou dobu. Základy řešení toho problému jak vyvíjet a trénovat řešení systémů umělé inteligence, aniž by došlo ke sdílení konkrétních citlivých dat uživatele, je již poměrně dlouho používané. Za průkopníka jsou v tomto směru považováni výrobci chytrých telefonů a jejich operačních systémů, zejména společnosti Apple a Google. Jde o tzv. federované učení (z anglického Federated learning).
Jednoduchý příklad:
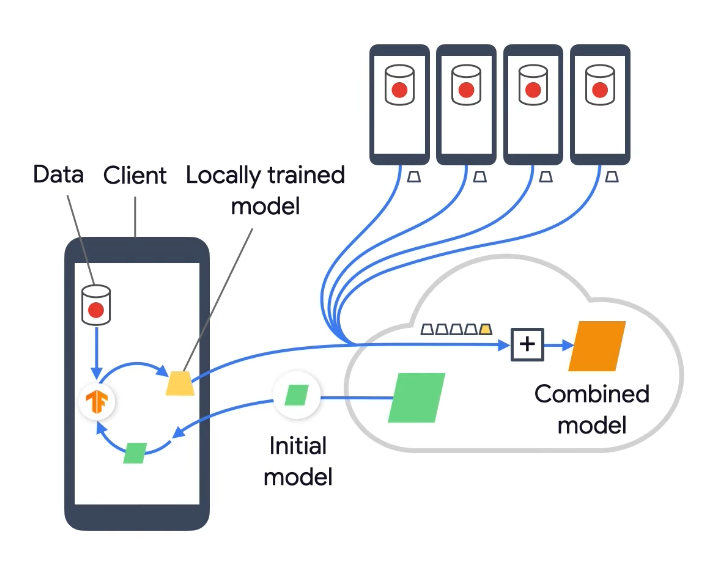 Pokud zákazník chytrého telefonu stiskne ve své aplikaci pro zprávy písmeno A, objeví se nějaká slova, například "And". Pokud toto slovo nevyhovuje, pisatel pokračuje v psaní. Pokud stiskne A a L, systém navrhne slovo „ALL“. Pokud ho pak vybere a pokračuje v psaní a zadá například "all in", rovnou se například objeví termín "objednávka". A nedělá to jen jeho smartphone, ale všechna zařízení Google nebo Apple po celém světě. Byli nevědomky lokálně vyškoleni uživatelem. Pokud nyní vybere navrhované slovo, pokračuje se v trénování modelu na smartphonu.
Pokud zákazník chytrého telefonu stiskne ve své aplikaci pro zprávy písmeno A, objeví se nějaká slova, například "And". Pokud toto slovo nevyhovuje, pisatel pokračuje v psaní. Pokud stiskne A a L, systém navrhne slovo „ALL“. Pokud ho pak vybere a pokračuje v psaní a zadá například "all in", rovnou se například objeví termín "objednávka". A nedělá to jen jeho smartphone, ale všechna zařízení Google nebo Apple po celém světě. Byli nevědomky lokálně vyškoleni uživatelem. Pokud nyní vybere navrhované slovo, pokračuje se v trénování modelu na smartphonu.
Večer, když je telefon nabitý, přístroj modely vycvičí a připraví k expedici. Jakmile je smartphone opět online, odešle natrénovaný model vývojářům Googlu nebo Applu. Takto se neodesílají žádná konkrétní osobní data uživatele, ale jen již zašifrované natrénované modely. Všechny informace zadané na smartphonu ho tak neopouštějí, opouštějí ho jen lokálně natrénované neuronové sítě AI. Vývojáři toho následně využívají pro další vývoj a vylepšování svých AI systémů a modelů a následně je posílají zpět nově vycvičené či vylepšené v rámci aktualizací. Cyklus neustálého zlepšování se tak vytváří bez sdílení konkrétních citlivých osobních dat. Tento princip se však dá podobně využívat i u strojů, včetně těch průmyslových.
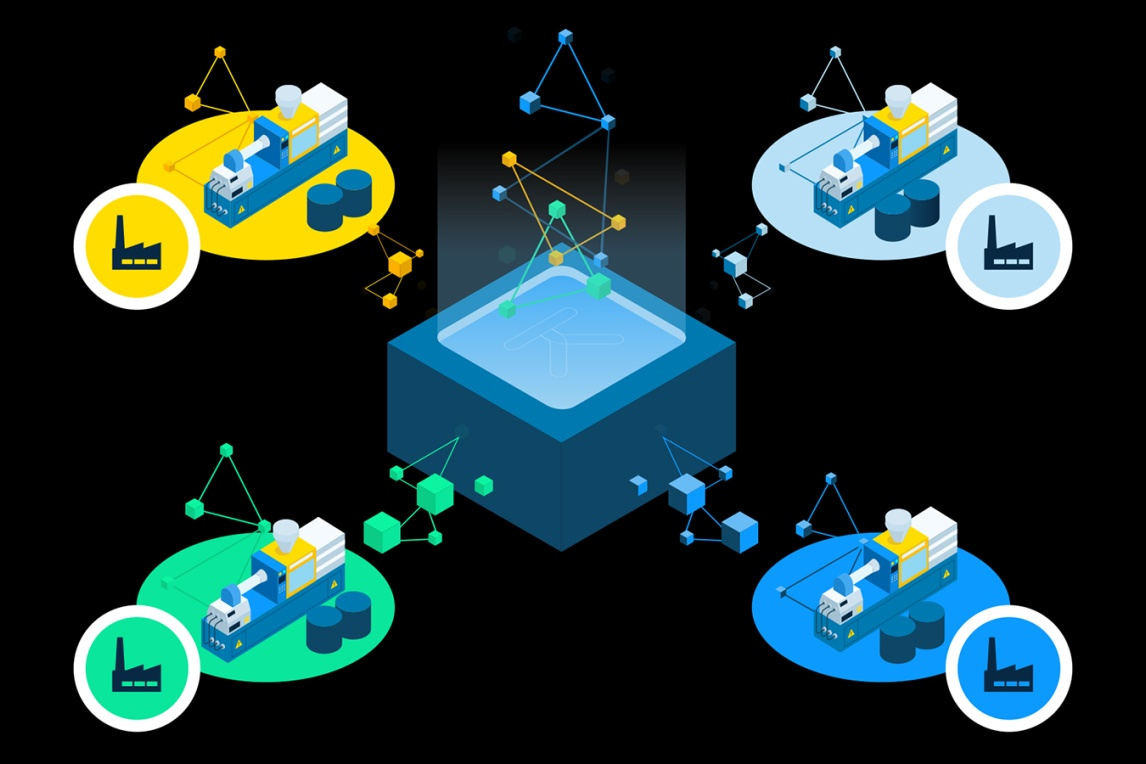
Federované učení spojuje částně lokálně trénované modely z jednotlivých provozů do jedné plně trénovaného modelu. Surová lokální trénovací data při tom nikdy neopustí oblast danou oblast každé lokální jednotky (počítače, provozu, továrny, pobočky).
Jak se principiálně realizuje federované učení?
Ve federovaném učení nejsou prvním krokem modely umělé inteligence, ale infrastruktura a vývojové nástroje, které umožňují pracovat s daty, ke kterým není přímý přístup. Distribuované sítě s edge zařízeními, cloudovými připojeními a pak v různých geografických lokalitách s omezenou konektivitou jsou každodenní záležitostí.
Federované učení pak následně lze rozdělit do tří různých kroků nebo fází:
- Federované učení obvykle začíná obecným modelem, který funguje jako základní linie a je trénován na centrálním serveru. V prvním kroku je tento generický model odeslán klientům aplikace. Tyto místní kopie jsou pak trénovány na datech generovaných klientskými systémy, učí se a zlepšují jejich výkon.
- Ve druhém kroku všichni klienti pošlou své naučené parametry modelu na centrální server. To se děje pravidelně podle stanoveného plánu. Modely zákazníka jsou také šifrovány, takže z dat nelze vyvozovat žádné závěry.
- Ve třetím kroku server agreguje naučené parametry, když je obdrží. Po agregaci parametrů je centrální model aktualizován a znovu sdílen s klienty. Celý proces se pak opakuje.
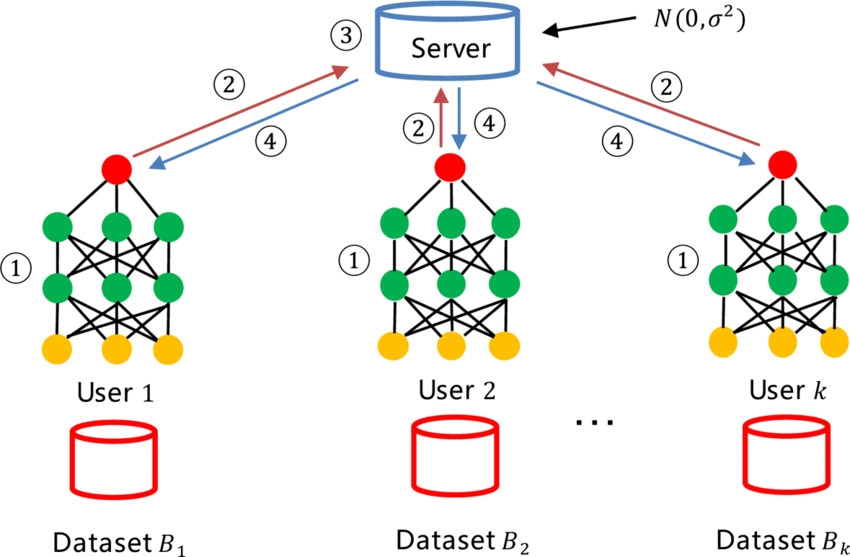
Při federovaném učení se z každé lokální jednotky / zařízení "Users"
přenášejí je částečně natrénované modely "Datasets" a ty se pak následně "spojují" do jednoho plně natrénovaného modelu.
Závěr
Protože se v systému federovaného učení přímo nepřenášejí žádná citlivá uživatelská data, lze jej využívat i u učení modelů v tak na únik dat citlivých odvětví, jako jsou lékařství nebo právní aplikace, například pro trénování modulů AI pro detekce podvodů a či různé diagnostické lékařské modely.
Toto řešení tak je zajímavé i pro průmyslové společnosti, které se obávají o svoje know-how a možného zneužití svých provozních či výrobních dat externí vývojářskou společností / výrobcem dodávaných systémů a zařízení.
Odkazy:
- Článek na webu Hannover Messe: https://www.hannovermesse.de/en/news/news-articles/how-machines-learn-from-each-other-without-learning-about-each-other



